Creating Clustered and Non-Clustered Indexes in SQL Server
In a SQL Server, two types of indexes exist; Clustered and non-clustered indexes. Both clustered indexes and non-clustered indexes have the same physical structure. Moreover, both of them are stored in SQL Server as a B-Tree structure.
Clustered index:
A clustered list is a particular type of index that rearranges the physical storage of records in the table. Within SQL Server, indexes are used to speed up database operations, leading to high performance. The table can, therefore, have only one clustered index, which is usually done on the primary key. A clustered index’s leaf nodes contain “data pages”. A table can possess only one clustered index.
Let us create a clustered index to have a better understanding. First of all, we need to create a database.
Database creation
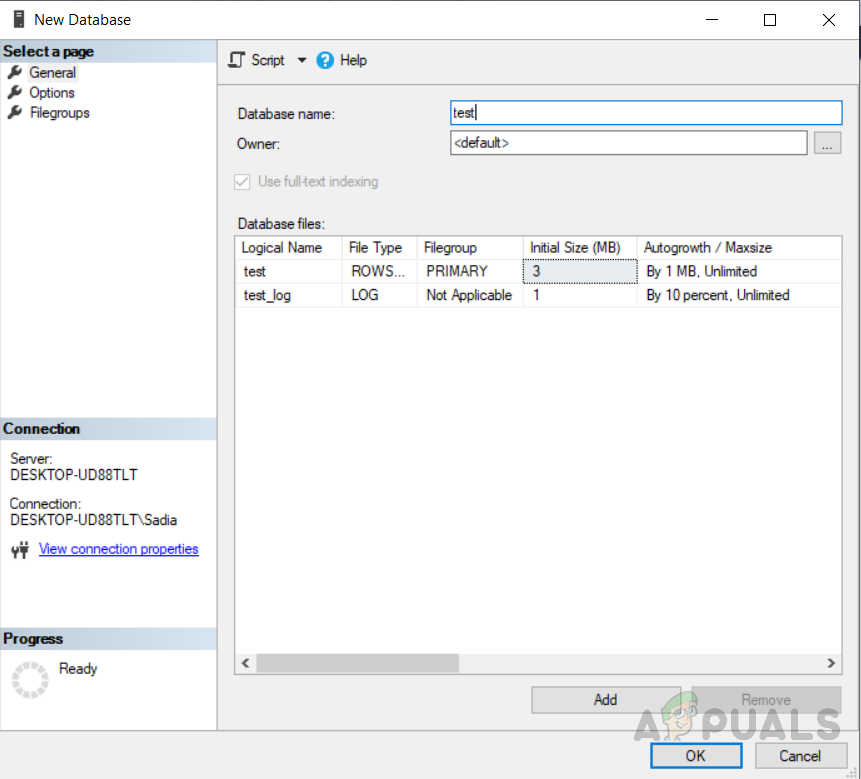
In order to create a database. Right-click on “Databases” in object explorer, and select “New database” option. Type the name of the database and click on ok. The database has been created as shown in the figure below.
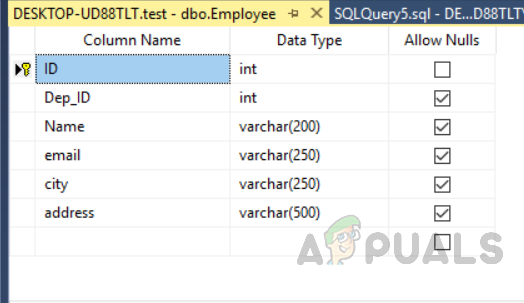
Now we will create a table named “Employee” with the primary key by using the design view. We can see in the picture below we have assigned primarily to the filed named “ID” and we have not created any index on the table.
You can also create a table by executing the following code.
USE [test] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Employee]( [ID] [int] IDENTITY(1,1) NOT NULL, [Dep_ID] [int] NULL, [Name] [varchar](200) NULL, [email] [varchar](250) NULL, [city] [varchar](250) NULL, [address] [varchar](500) NULL, CONSTRAINT [Primary_Key_ID] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
The output will be as follows.
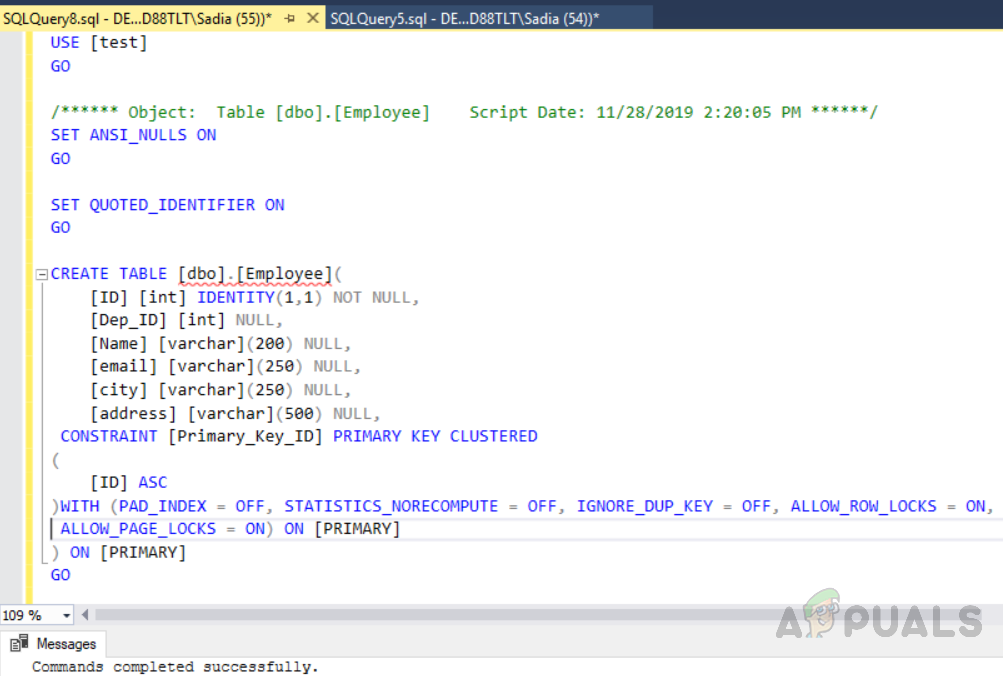
The above code has created a table named “Employee” with an ID field, a unique identifier as a primary key. Now in this table, a clustered index will be automatically created on column ID due to primary key constraints. If you want to see all the indexes on a table run the stored procedure “sp_helpindex”. Execute the following code to see all the indexes on a table named “Employee”. This store procedure takes a table name as an input parameter.
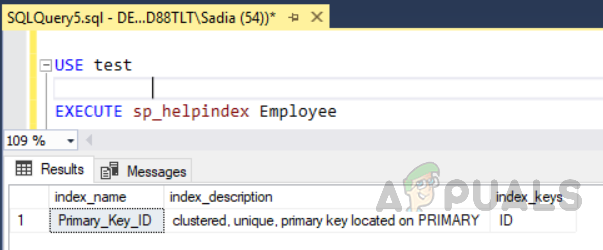
USE test EXECUTE sp_helpindex Employee
The output will be as follows.
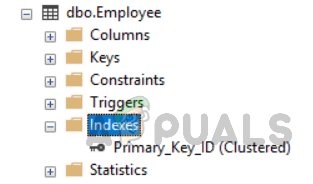
Another way to view table indexes is to go to “tables” in object explorer. Select the table and expend it. In the indexes folder, you can see all the indexes relevant to that specific table as shown in the figure below.
As this is the clustered index so the logical and physical order of the index will be the same. This means if a record has an Id of 3, then it will be stored in the third row of the table. Similarly, if the fifth record has an id of 6, it will be stored in the 5th location of the table. In order to understand the ordering of records, you need to execute the following script.
USE [test] GO SET IDENTITY_INSERT [dbo].[Employee] ON INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (8, 6, N'Humbaerto Acevedo', N'humbaerto.acevedo@gmail.com', N'SAINT PAUL', N'895 E 7th St Saint Paul Mn 551063852') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (9, 6, N'Humbaerto Acevedo', N'humbaerto.acevedo@gmail.com', N'SAINT PAUL', N'895 E 7th St Saint Paul Mn 551063852') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (10, 7, N'Pilar Ackaerman', N'pilar.ackaerman@gmail.com', N'ATLANTA', N'5813 Eastern Ave Hyattsville Md 207822201') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (11, 1, N'Aaaronboy Gutierrez', N'aronboy.gutierrez@gmail.com', N'HILLSBORO', N'5840 Ne Cornell Rd Hillsboro Or 97124') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (12, 2, N'Aabdi Maghsoudi', N'abdi_maghsoudi@gmail.com', N'BRENTWOOD', N'987400 Nebraska Medical Center Omaha Ne 681987400') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (13, 3, N'Aabharana, Sahni', N'abharana.sahni@gmail.com', N'HYATTSVILLE', N'2 Barlo Circle Suite A Dillsburg Pa 170191') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (14, 3, N'Aabharana, Sahni', N'abharana.sahni@gmail.com', N'HYATTSVILLE', N'2 Barlo Circle Suite A Dillsburg Pa 170191') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (1, 1, N'Aaaronboy Gutierrez', N'aronboy.gutierrez@gmail.com', N'HILLSBORO', N'5840 Ne Cornell Rd Hillsboro Or 97124') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (2, 2, N'Aabdi Maghsoudi', N'abdi_maghsoudi@gmail.com', N'BRENTWOOD', N'987400 Nebraska Medical Center Omaha Ne 681987400') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (3, 3, N'Aabharana, Sahni', N'abharana.sahni@gmail.com', N'HYATTSVILLE', N'2 Barlo Circle Suite A Dillsburg Pa 170191') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (4, 3, N'Aabharana, Sahni', N'abharana.sahni@gmail.com', N'HYATTSVILLE', N'2 Barlo Circle Suite A Dillsburg Pa 170191') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (5, 4, N'Aabish Mughal', N'abish_mughal@gmail.com', N'OMAHA', N'2975 Crouse Lane Burlington Nc 272150000') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (6, 5, N'Aabram Howell', N'aronboy.gutierrez@gmail.com', N'DILLSBURG', N'868 York Ave Atlanta Ga 303102750') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (7, 5, N'Aabram Howell', N'aronboy.gutierrez@gmail.com', N'DILLSBURG', N'868 York Ave Atlanta Ga 303102750') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (15, 4, N'Aabish Mughal', N'abish_mughal@gmail.com', N'OMAHA', N'2975 Crouse Lane Burlington Nc 272150000') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (16, 5, N'Aabram Howell', N'aronboy.gutierrez@gmail.com', N'DILLSBURG', N'868 York Ave Atlanta Ga 303102750') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (17, 5, N'Aabram Howell', N'aronboy.gutierrez@gmail.com', N'DILLSBURG', N'868 York Ave Atlanta Ga 303102750') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (18, 6, N'Humbaerto Acevedo', N'humbaerto.acevedo@gmail.com', N'SAINT PAUL', N'895 E 7th St Saint Paul Mn 551063852') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (19, 6, N'Humbaerto Acevedo', N'humbaerto.acevedo@gmail.com', N'SAINT PAUL', N'895 E 7th St Saint Paul Mn 551063852') INSERT [dbo].[Employee] ([ID], [Dep_ID], [Name], [email], [city], [address]) VALUES (20, 7, N'Pilar Ackaerman', N'pilar.ackaerman@gmail.com', N'ATLANTA', N'5813 Eastern Ave Hyattsville Md 207822201') SET IDENTITY_INSERT [dbo].[Employee] OFF
Although records are stored in the “Id” column in a random order of values. But due to clustered index on the id column. Records are physically stored in ascending order of values in the id column. To verify this we need to execute the following code.
Select * from test.dbo.Employee
The output will be as follows.
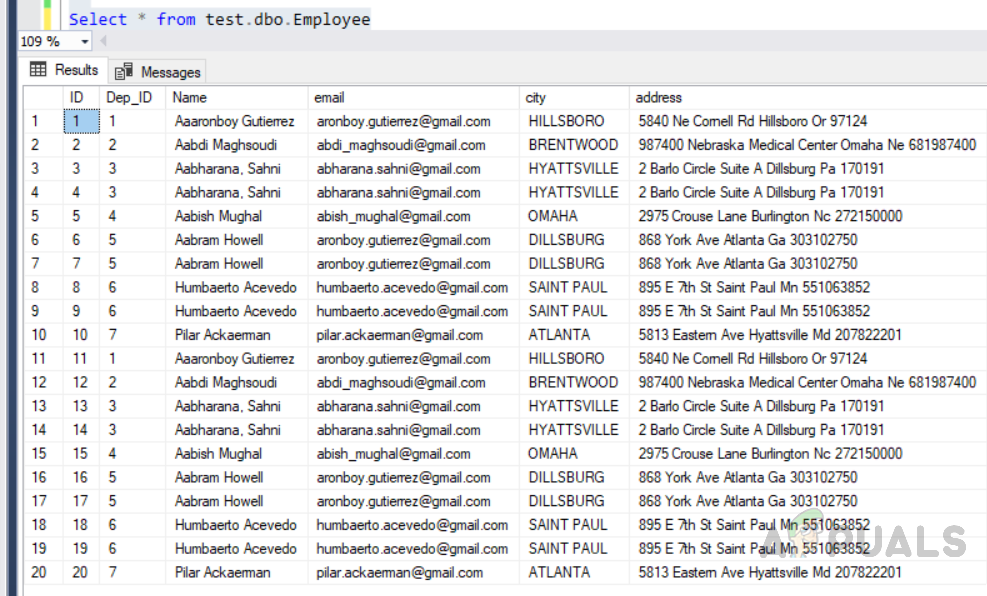
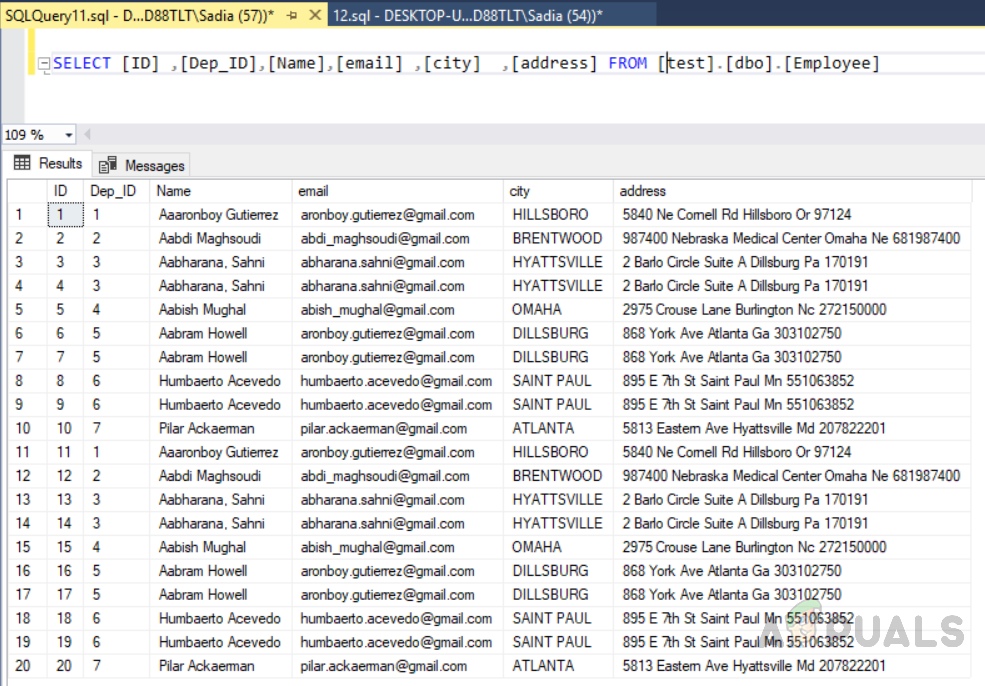
We can see in the above figure records have been retrieved in the ascending order of values in the id column.
Customized clustered index
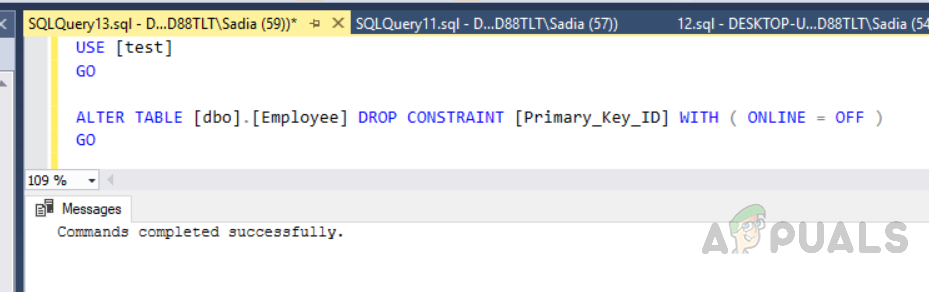
You can also create a custom clustered index. As we can create only one clustered index so we need to delete the previous one. In order to delete the index, execute the following code.
USE [test] GO ALTER TABLE [dbo].[Employee] DROP CONSTRAINT [Primary_Key_ID] WITH ( ONLINE = OFF ) GO
The output will be as follows.
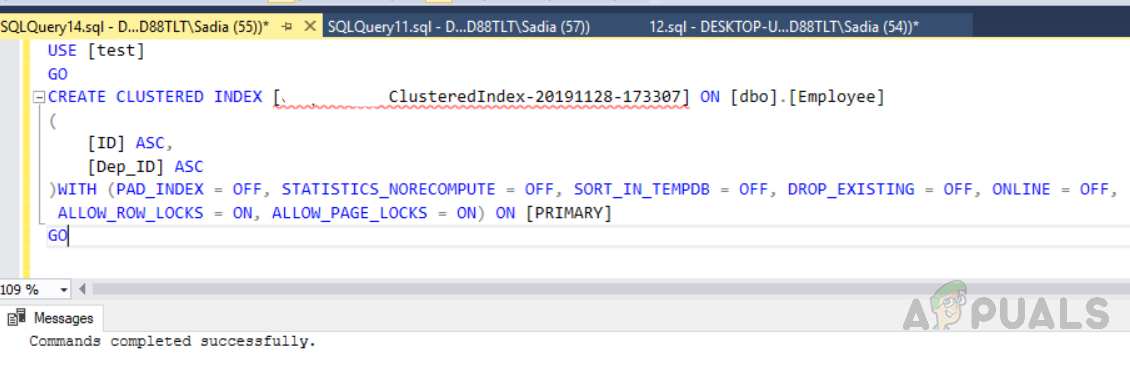
Now in order to create the index execute the following code in a query window. This index has been created on more than one columns so it is called a composite index.
USE [test] GO CREATE CLUSTERED INDEX [ClusteredIndex-20191128-173307] ON [dbo].[Employee] ( [ID] ASC, [Dep_ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
The output will be as follows
We have created a custom clustered index on ID and Dep_ID. This will sort rows according to Id and then by Dep_Id. In order to view this execute the following code. The result will be ascending order of ID and then By Dep_id.
SELECT [ID] ,[Dep_ID],[Name],[email] ,[city] ,[address] FROM [test].[dbo].[Employee]
The output will be as follows.
Non-clustered index:
A non-clustered index is a particular index type in which the index’s logical order does not match the rows ‘ physical order stored on the disk. The leaf node of the non-clustered index does not contain data pages rather it contains information about index rows. A table can possess up to 249 indexes. By default, a Unique Key restriction creates a Nonclustered Index. In the read operation, non-clustered indexes are slower than clustered indexes. A non-clustered index has a copy of the data from the indexed columns kept in order along with references to the actual data rows; pointers to the clustered list if any. Therefore it’s a good idea to select only those columns that are being used in the index instead of using *. This way data can be fetched directly from the duplicate index. An otherwise clustered index is also used to select remaining columns if it is created.
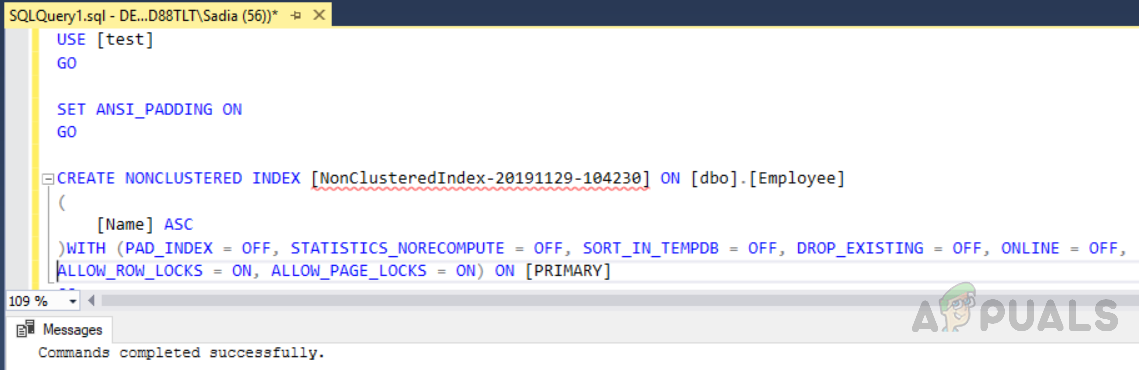
The syntax used to create a nonclustered index is similar to the clustered index. However, the keyword “NONCLUSTERED” is used instead of “CLUSTERED” in the case of the non-clustered index. Execute the following script in order to create a non clustered index.
USE [test] GO SET ANSI_PADDING ON GO CREATE NONCLUSTERED INDEX [NonClusteredIndex-20191129-104230] ON [dbo].[Employee] ( [Name] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
The output will be as follows.
The table records are sorted by a clustered index if it has been created. This new non clustered index will sort the table according to its definition and will be stored in a separate physical address. The above script will create the index on the “NAME” column of the Employee table. This index will sort the table in ascending order of column “Name”. The table data and index will be stored in different locations, as we said earlier. Now execute the following script in order to view the impact of a new non clustered index.
select Name from Employee
The output will be as follows.
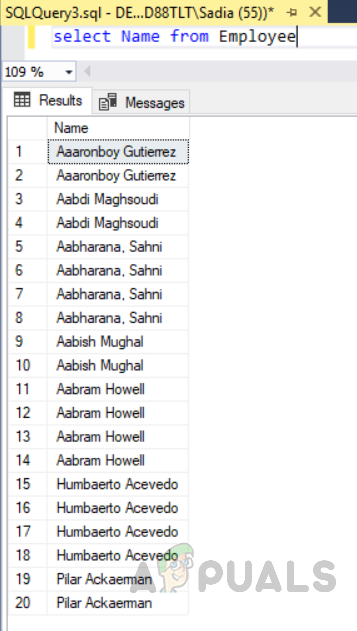
We can see in the figure above that the Name column of the table Employee has been shown in ascending order of name column, although we have not mentioned the “Order by ASC” clause with the select clause. This is because of the non-clustered index on the “Name” column created on the Employee table. Now if a query is written to retrieve Name, email, city, and address of the specific person. The database will first search for that specific name inside the index, and then retrieve relevant data which will decrease query fetch time, especially when data is huge.
select Name, email, city, address from Employee where name='Aaaronboy Gutierrez'
Conclusion
From the above discussion, we came to know that the clustered index can be only one whereas non- clustered index can be many. The clustered index is faster as compared to non- clustered index. The clustered index does not consume extra storage space whereas the non-clustered index needs extra memory to store them. If we apply a primary key constraint on the table clustered index is automatically created on it. Moreover, if we apply a unique key constraint on any column a non- clustered index is automatically created on it. Non clustered index is faster as compared to clustered ones for insert and update operation. A table may not have any non-clustered index.