AMD Launches Instinct MI300 Accelerators at the Advancing AI Event

After several teasers, AMD’s Instinct MI300 Accelerators are finally available for interested consumers. MI300 aims to revolutionize the exascale AI industry, offering the first integrated CPU and GPU package.
MI300 offers diversity for the AI market, coming in both CPU and CPU+GPU configurations. The MI300A is effectively a data-center APU, using EPYC ‘Zen 4‘ cores and the data-center CDNA3 architecture. On the flip side, the MI300X is a pure data-center GPU, replacing the MI250X.
- (Versus CDNA2)
- 3.4x Higher BF16 Performance
- 6.8x Higher INT8 Performance
- 1.6x More Memory Bandwidth
MI300X Architecture Analysis
The MI300X is a direct competitor to NVIDIA’s Hopper and Intel’s Gaudi offerings. AMD has opted for a 2.5D+3D Hybrid packaging solution, which is crucial for this design to follow through. It is amazing to see how AMD has managed to stack so many chips together. It should go without saying that packaging is the heart of the MI300.
Starting off, the interposer features a passive die, which has all the I/O and cache. This passive die is actually the base die, featuring 4x 6nm chiplets, the I/O Dies. On top of this base die, we have 8 GPU XCDs. To supply these XCDs with memory, there are 8 HBM3 chiplets, enabling up to 192GB of memory (5.3TB/s), 50% higher than the MI250X.

- 304 CDNA3 Compute Units
- 8 XCDs Stacked on top of the Base Die
- 256MB Infinity Cache
- 4 I/O Dies in the Base Die
- 153 Billion Transistors
- 8 Stacks of HBM3 for 192GB of Memory
- 5.3TB/s of Memory Bandwidth
As each XCD has 40 Compute Units, the MI300X can pack 304 CUs (due to yields) which is more than 3x than the Radeon RX 7900 XTX. Moreover, the MI300X is a powerhouse, consuming 750W of power.
MI300A Architecture Overview
AMD’s MI300A uses a unified memory structure, wherein both the GPU and CPU share the same memory space. By memory, we are referring to stacks of HBM3. This allows quick and low-latency transfer of data between the CPU and GPU. Since there’s no intermediary, you’d expect almost instant response times.

The MI300A is very similar in design to the MI300X, except for the fact it features Zen4 cores and TCO-optimized memory capacities. 2 XCDs have been replaced in favor of 3 Zen4-based CCDs, each with 8-cores. This allows the MI300 to ship with a maximum of 24 Zen4 cores alongside 228 CUs.
- 228 CDNA3 Compute Units
- 6 XCDs Stacked on top of the Base Die
- 256MB Infinity Cache
- 3 CCDs or 24 Zen4 Cores
- 146 Billion Transistors
- 8 Stacks of HBM3 for 128GB of Memory
- 5.3TB/s of Memory Bandwidth
The MI300A offers 128GB of HBM3 memory, with speeds of up to 5.3TB/s. It is built using 146 Billion transistors and in terms of compute, it can output 122 TeraFLOPS of FP32 and 61 TeraFLOPS of FP64 performance. The MI300A has entered production and will be available next year.
Platform Advantage
Behold the most powerful Generative AI computer in the world. What you see are 8x MI300X GPUs and two EPYC 9004 CPUs, connected via Infinity Fabric in an OCP-compliant package. Using this board is as simple as plugging and playing since most systems follow OCP specs. As a side note, this board consumes a whopping 18kW of power.
The MI300X platform supports all connectivity and networking capabilities that NVIDIA’s H100 HGX platform has. However, it has 2.4x more memory and 1.3x more compute power.

Performance Metrics
-MI300X Performance
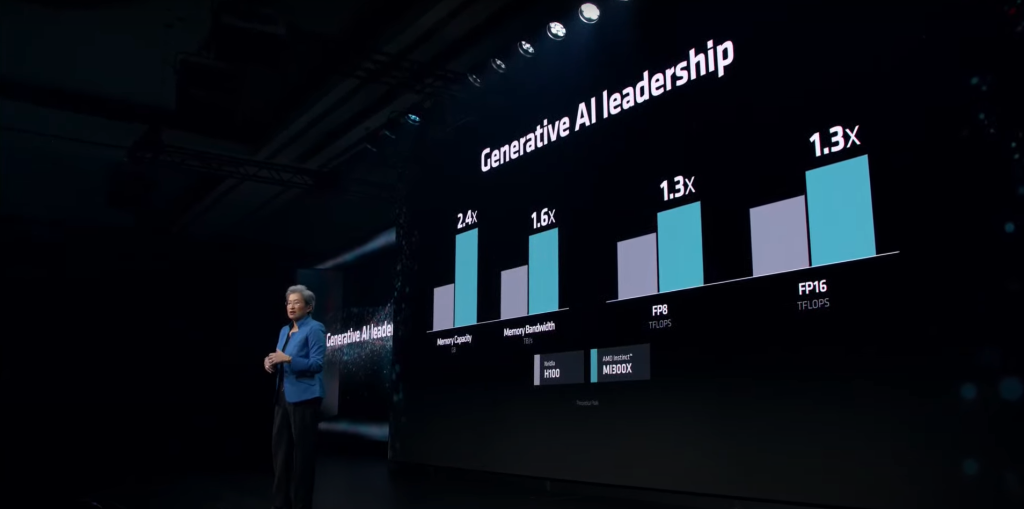
AMD promises 1.3 PetaFLOPS of FP16 performance and 2.6 PetaFLOPS of FP8 performance with the MI300X. Against NVIDIA’s Hopper-based H100, the MI300X is actually significantly faster in both FP16 and FP8 workloads. This lead extends to memory capacity and memory bandwidth, which is obvious, but plays a major role in LLM training.
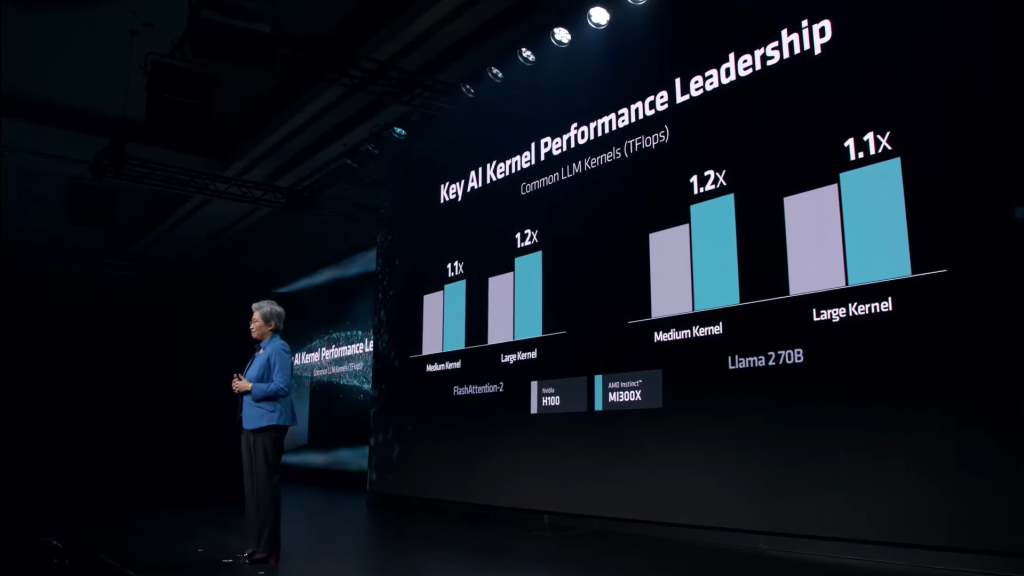
In various LLM Kernels, the MI300X maintains a steady lead against the H100. These Kernels include FlashAttention-2 and the Llama 2 70B model.
In AI Inference, the MI300X smokes NVIDIA’s H100 in both Llama and Bloom, which is the world’s largest multiple-language AI model. AMD is showing off pretty insane numbers, with up to 60% faster performance than NVIDIA.

Performance Summary:
- (Versus Hopper H100)
- 2.4x Higher Memory Capacity
- 1.6x Higher Memory Bandwidth
- 1.3x FP8 TFLOPS
- 1.3x FP16 TFLOPS
- 1.4x Llama 2 70B Performance (8v8)
- 1.6x Bloom 176B Performance (8v8)
-MI300A Performance
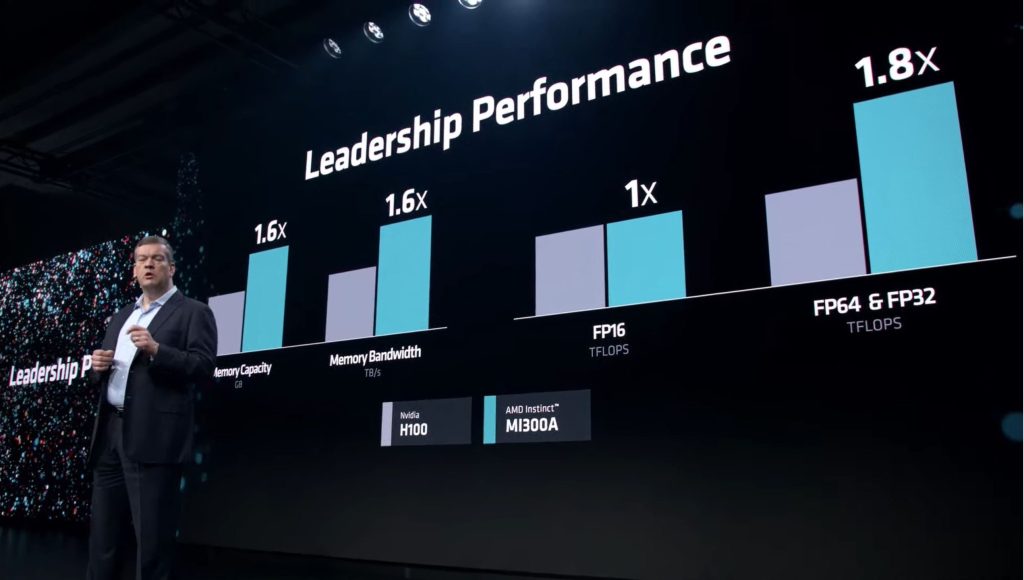
The MI300A has 1.6x more memory and 1.6x higher bandwidth than NVIDIA’s H100. It is at parity in FP16 compute, but eclipses the H100 in FP64 and FP32 by 80%.
Similarly, the MI300A is 4x faster than the H100 in OpenFOAM. Most of this improvement comes from the unified memory architecture, higher bandwidth, and more memory capacity.

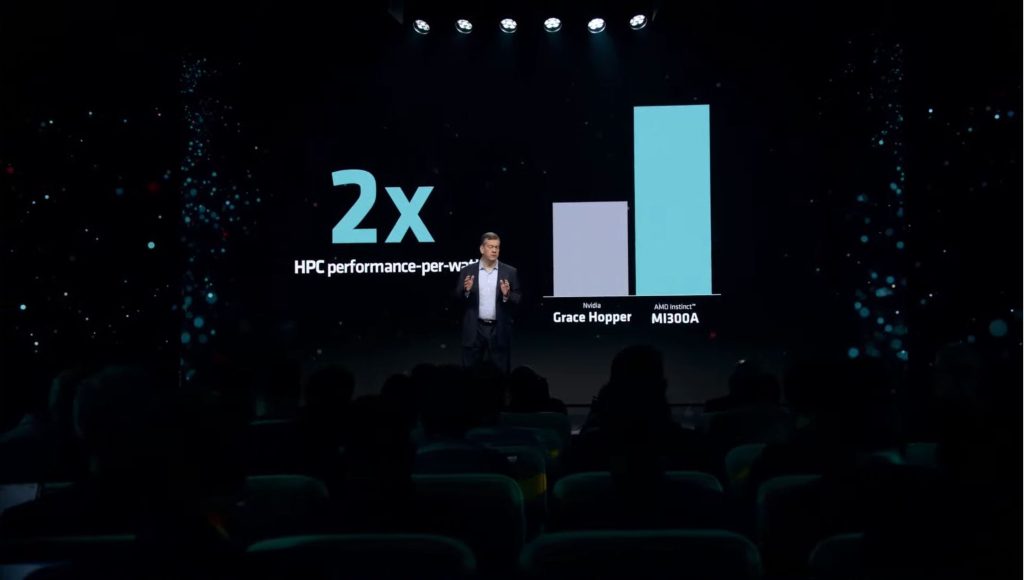
This may seem outlandish, but AMD is claiming that the MI300A is 2x more efficient than NVIDIA’s Grace Hopper super chip. We are unaware of methods and benchmarks used to achieve this metric, although this is massive, even in certain scenarios.
The MI300A will power the world’s most capable and fastest AI supercomputer, El Capitan. Using the MI300A, El Capitan blasts through the ExaFLOP barrier, yes ExaFLOP (1018), 16x faster than LLNL’s current supercomputer.

Performance Summary:
- (Versus Hopper H100)
- 1.6x Higher Memory Capacity
- 1.6x Higher Memory Bandwidth
- 1.8x FP32 and FP64 TFLOPS
- 4x Faster Performance in OpenFOAM
- (Versus Grace-Hopper Superchip)
- 2x More Efficient
Summary
The AI market will only get more competitive as the years pass. While NVIDIA was making hay with its Hopper lineup, AMD has come right in time to snatch NVIDIA’s market share. NVIDIA is readying its Blackwell B100 GPUs to deliver record-breaking data-center performance, arriving next year. Likewise, Intel’s Guadi 3 and Falcon Shores GPUs are also in the works.





