How to Fix “Column Is Invalid in the Select List” in SQL Server
The error “Column is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause” appears when a query uses GROUP BY but also selects a column that SQL Server cannot reduce to a single value for each group.

In simple terms, once rows are grouped, SQL Server can only return:
- columns included in the GROUP BY clause, or
- columns summarized with an aggregate function such as SUM(), AVG(), COUNT(), MIN(), or MAX().
If a selected column is neither grouped nor aggregated, SQL Server does not know which single value to show for that group, so it throws this error.
What This Error Means?
GROUP BY is used when you want to summarize rows. For example, you might want:
- the average salary for each department
- the number of people in each state
- the highest sale in each category
When SQL Server groups rows, it combines multiple records into one result row per group. Because of that, every selected value must either identify the group or summarize the rows inside it.
You can think of it as split, apply, combine:
- Split: divide rows into groups
- Apply: run an aggregate function on each group
- Combine: return one row per group
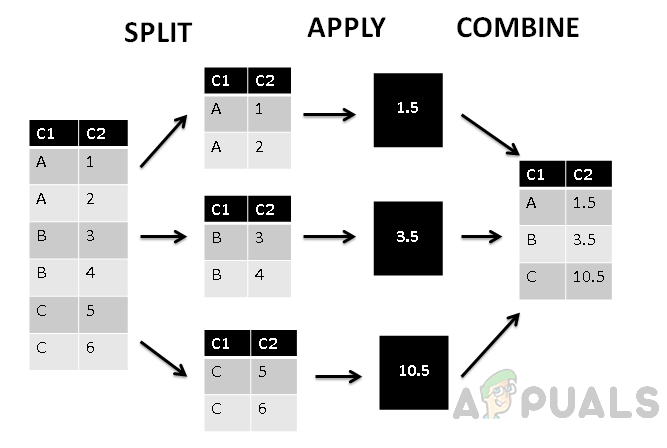
In the figure above, values in column C1 are grouped, an aggregate function is applied to each group, and one result row is returned for each group.
How to Fix the Error?
There are two logical ways to fix this error.
Fix 1: Add the column to the GROUP BY clause
Use this when you want separate results for each distinct value of that column.
Fix 2: Wrap the column in an aggregate function
Use this when you want one summarized value per group.
In most cases, the second option is what you actually want, because the purpose of GROUP BY is usually to summarize data.
Example 1: Grouping Employee Salaries
Here is an example using a database named appuals.
Create a table called employee:
USE [appuals]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[employee](
[e_id] [int] NOT NULL,
NULL,
[dep_id] [int] NULL,
[salary] [int] NULL,
CONSTRAINT [PK_employee] PRIMARY KEY CLUSTERED
(
[e_id] ASC
)
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO 
Insert sample data:
INSERT INTO employee(e_id, e_ename, dep_id, salary) VALUES (101, 'Sadia', 1, 6000), (102, 'Saba', 1, 5000), (103, 'Sana', 2, 4000), (104, 'Hammad', 2, 3000), (105, 'Umer', 3, 4000), (106, 'Kanwal', 3, 2000)
To view all rows:
SELECT * FROM employee

Wrong Query
SELECT dep_id, salary FROM employee GROUP BY dep_id
Error: Column ’employee.salary’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
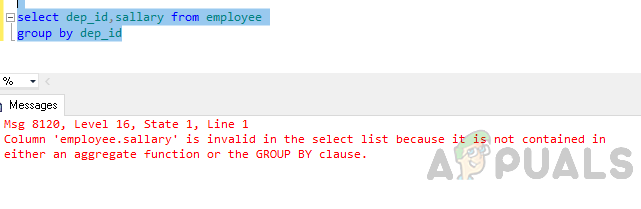
Why it fails: the query groups by dep_id, but salary is not grouped and not aggregated. Since one department can have multiple salary values, SQL Server cannot choose just one salary to return.
Correct Query
SELECT dep_id, AVG(salary) AS average_salary FROM employee GROUP BY dep_id
Why this works: AVG(salary) summarizes all salary values inside each department, so SQL Server can return one row per department with one calculated result.
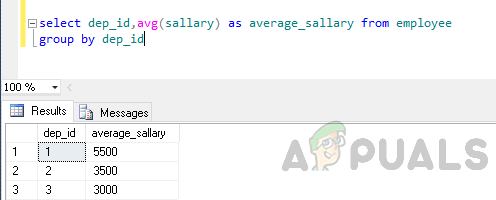
This follows the same split, apply, combine pattern shown below:

Common Aggregate Functions
These are the most common functions used with GROUP BY:
- SUM() returns the total for each group.
- COUNT() returns the number of rows in each group.
- AVG() returns the average value in each group.
- MIN() returns the smallest value in each group.
- MAX() returns the largest value in each group.
Example 2: Counting People by State
Now let’s look at another practical example.
Create a table named people:
USE [appuals]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[people](
[id] [bigint] IDENTITY(1,1) NOT NULL,
NULL,
NULL,
NULL,
[age] [int] NULL
) ON [PRIMARY]
GO 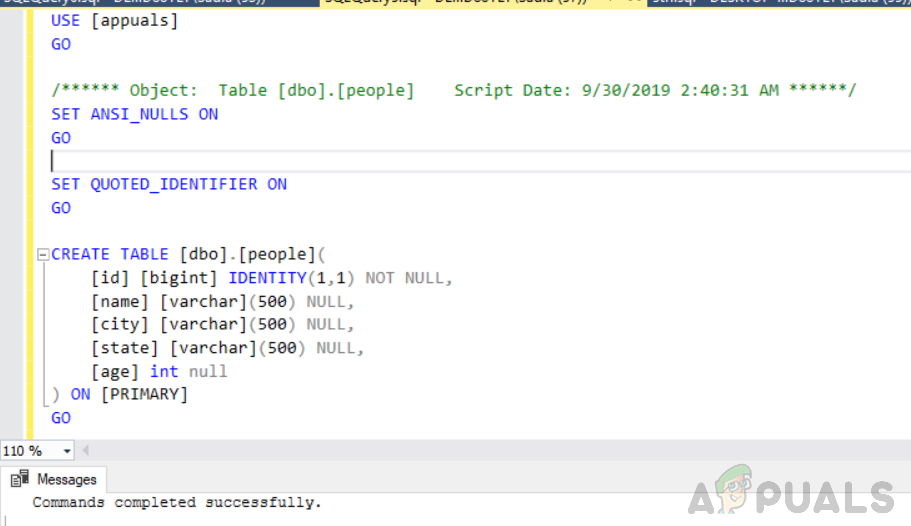
Insert sample data:
INSERT INTO people(name, city, state, age)
VALUES
('Meggs', 'MONTEREY', 'CA', 20),
('Staton', 'HAYWARD', 'CA', 22),
('Irons', 'IRVINE', 'CA', 25),
('Krank', 'PLEASANT', 'IA', 23),
('Davidson', 'WEST BURLINGTON', 'IA', 40),
('Pepewachtel', 'FAIRFIELD', 'IA', 35),
('Schmid', 'HILLSBORO', 'OR', 23),
('Davidson', 'CLACKAMAS', 'OR', 40),
('Condy', 'GRESHAM', 'OR', 35) 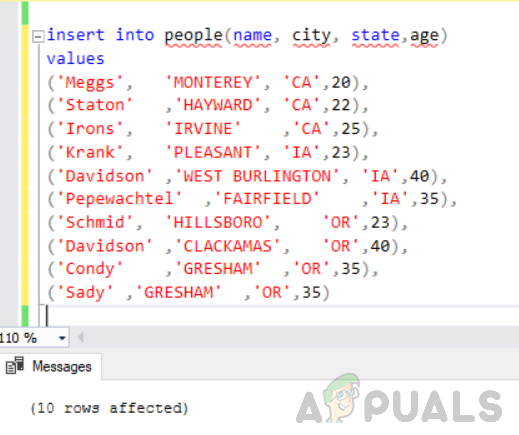
Correct Query
Suppose you want to find the number of residents and the average age for each state:
SELECT state, AVG(age) AS Age, COUNT(*) AS no_of_residents FROM people GROUP BY state
Why this works: state identifies each group, while AVG(age) summarizes ages and COUNT(*) counts rows within that state.

Wrong Query
SELECT state, age, COUNT(*) AS no_of_residents FROM people GROUP BY state
Error: Column ‘people.age’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.

Why it fails: one state can contain many people with different ages, so SQL Server cannot return a single age value unless you either group by it or summarize it.
Logical Fix
SELECT state, AVG(age) AS Age, COUNT(*) AS no_of_residents FROM people GROUP BY state
This returns one row per state along with the average age and resident count for that state.
Important GROUP BY Rules
- GROUP BY comes after WHERE and before ORDER BY.
- Use WHERE to filter rows before grouping.
- Every selected column must be either grouped or aggregated.
- NULL values are treated as one group.
GROUP BY with NULL Values
A real NULL is not the same as an empty string ”, and it is also not the same as the text ‘NULL’. SQL Server treats them differently.
First, insert a row with an empty string in the state column:
INSERT INTO people(name, city, state, age)
VALUES ('Kanwal', 'GRESHAM', '', 35) 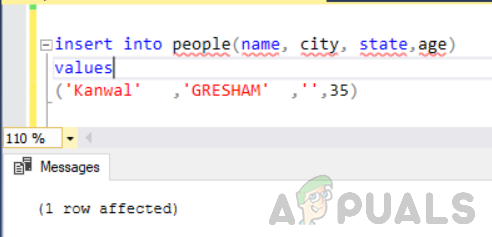
Now run:
SELECT state, AVG(age) AS Age, COUNT(*) AS no_of_residents FROM people GROUP BY state

The empty string is treated as its own group.
Now insert actual NULL values:
INSERT INTO people(name, city, state, age)
VALUES
('Kanwal', 'IRVINE', NULL, 35),
('Krank', 'PLEASANT', NULL, 23) 
Run the same query again:
SELECT state, AVG(age) AS Age, COUNT(*) AS no_of_residents FROM people GROUP BY state

All real NULL values are grouped together as one group. By contrast, the text ‘NULL’ would be treated as an ordinary string value.

SELECT “a”.”kode_brg”, “harga_beli”, “b”.”nama_brg”, MAX(“tgl_berlaku”) AS “tgl_berlaku” FROM “mcmharga_beli” “a” LEFT JOIN “mcmbarang” “b” ON “b”.”kode_brg” = “a”.”kode_brg” WHERE “a”.”tgl_berlaku” = ‘20200602’ AND “a”.”kode_brg” = ‘UHT03’ GROUP BY “b”.”kode_brg”.
so whats the problem here madam Sadia