AMD Aims to Break the ZettaFLOP Barrier by 2035, Lays Down Next-Gen Plans to Resolve Efficiency Problems

AMD recently presented its future plans and speculations regarding the future of supercomputing at the ISSCC. The company, headed by Dr.Lisa Su aims to break the ZetaFLOP barrier enabling Zetascale computing.
However, that comes with its own set of challenges that AMD will have to resolve one way or the other. It is pertinent to mention that AMD was the first ever company to exceed the ExaFLOP mark. The difference between both is not 10x, not 100x but 1000x. Given how semiconductors have started to slow down in terms of scaling, it will be a tedious challenge to achieve 1000x more performance while being efficient.
AMD’s Attempt at Breaking the ZetaFLOP Barrier
Dr.Lisa Su starts off by mentioning how far AMD has progressed in the last 10 years. Fun fact, the last she attended the ISSCC was 10 years ago, so it gives us a rough idea of how much AMD has advanced. In any case, the slide showcases an AMD mobile APU boasting 1.3 Billion transistors packed with 4 cores / 4 threads based on a 32nm Monolithic process with 4MB of total cache. Not too shabby for a 2013 product.
Next up is the Genoa EPYC 9654, which as you all know is probably the fastest x86 processor to date. It wields 90 Billion transistors, or 69x as much as the aforementioned mobile CPU. The core counts have been uplifted to 96 cores, but then again this is a server product.

Performance vs Efficiency
Moore’s Law still lives, but for how long? The chart you see below is a representation of the performance trend in server-oriented CPUs for the past 13 or so years. The scale is almost linear, leading to a 2x performance increment after every 2.4 years.

Supercomputing performance has also increased by almost 2x every 1.2 years so that’s much faster than mainstream CPUs. Interestingly, as per this chart, Zettascale computing can be enabled as early as 2035. But that’s not always how things work, at least in the semiconductor field.
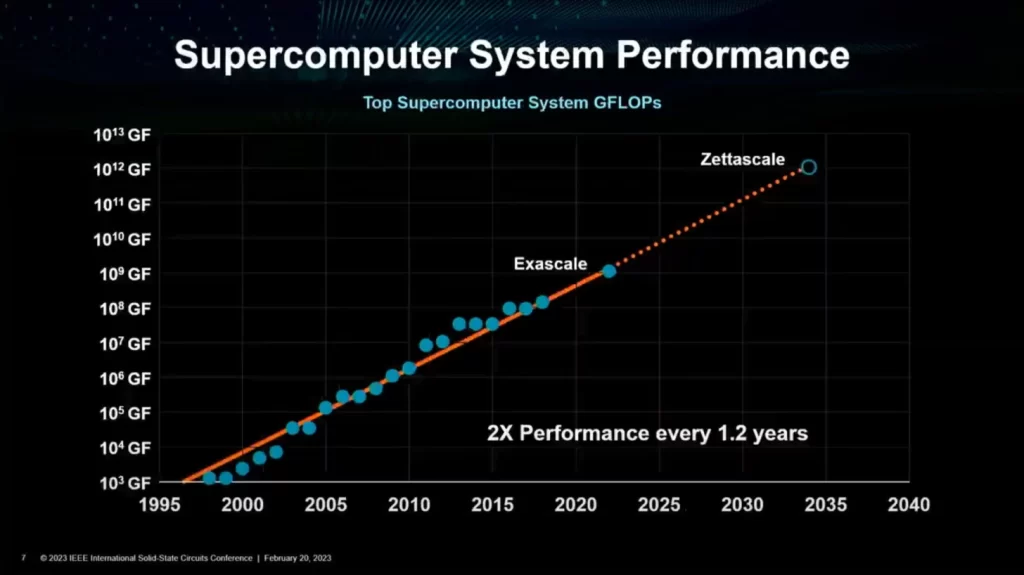
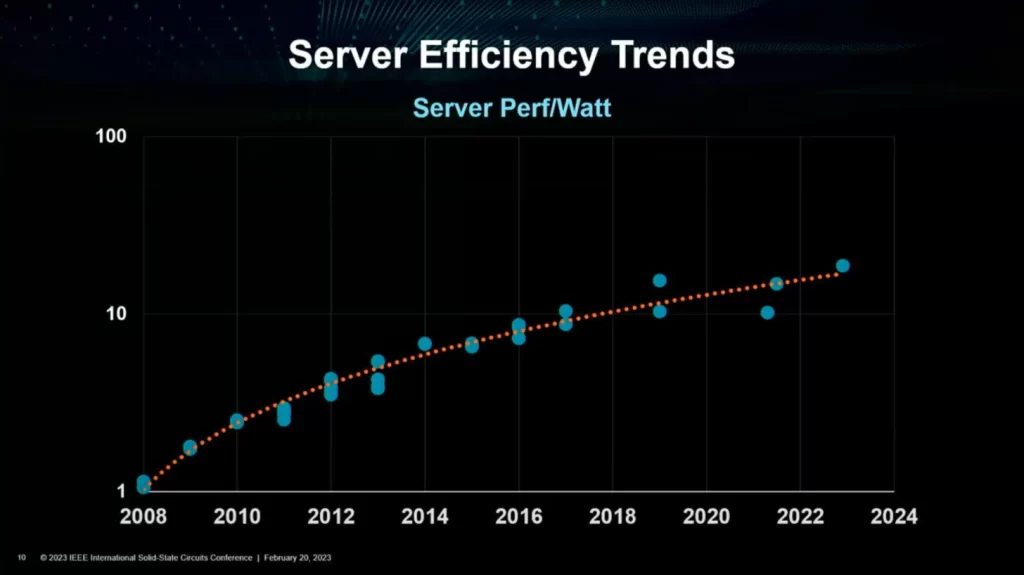
And this leads to stagnation if you factor in efficiency trends. Instead of going in a linear path, the slope has started to flatten out leading to lower efficiency. Take it like this, every generation will be more efficient than the last, but the changes will be less drastic.
The Challenge
Assuming we reach the ExaFLOP target by 2035, with 2x efficiency over every 2.2 years. If we do the maths, that single supercomputer would require 500MW of power. Create 2 such systems, and you’re looking at 1GW of power which is technically equal to the output of a Nuclear power plant. For reference, an Exascale system consumes only 21MW of power.
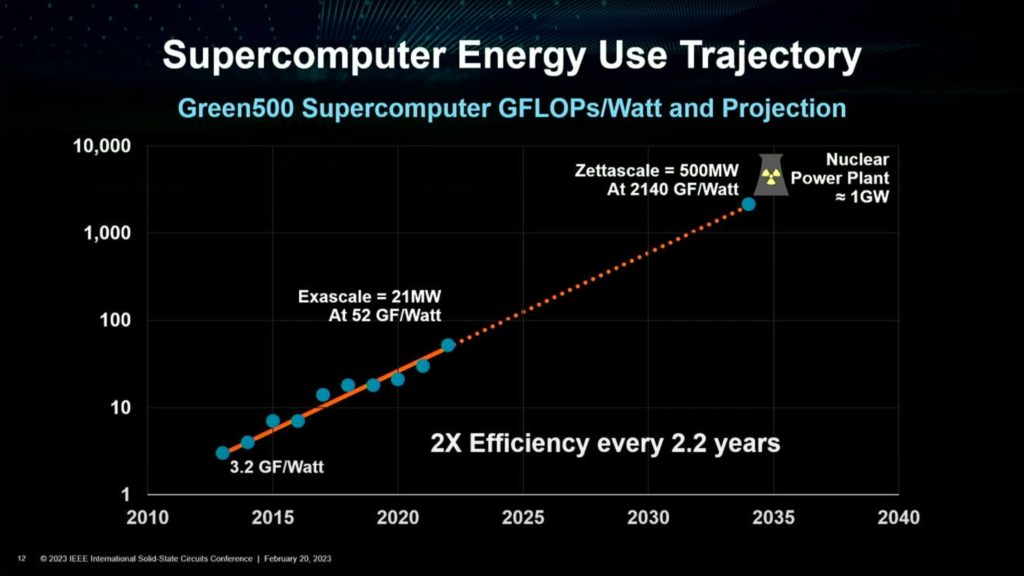
It is unanimously agreed that creating newer and faster nodes will indeed take more time and resources. Moore’s Law is slowing down and each process node will be more difficult to achieve.

As the data sets and the consumption of data increase, more and more memory and memory bandwidth are required to feed the systems. This is another major area that needs innovation in the next decade.

The Solution
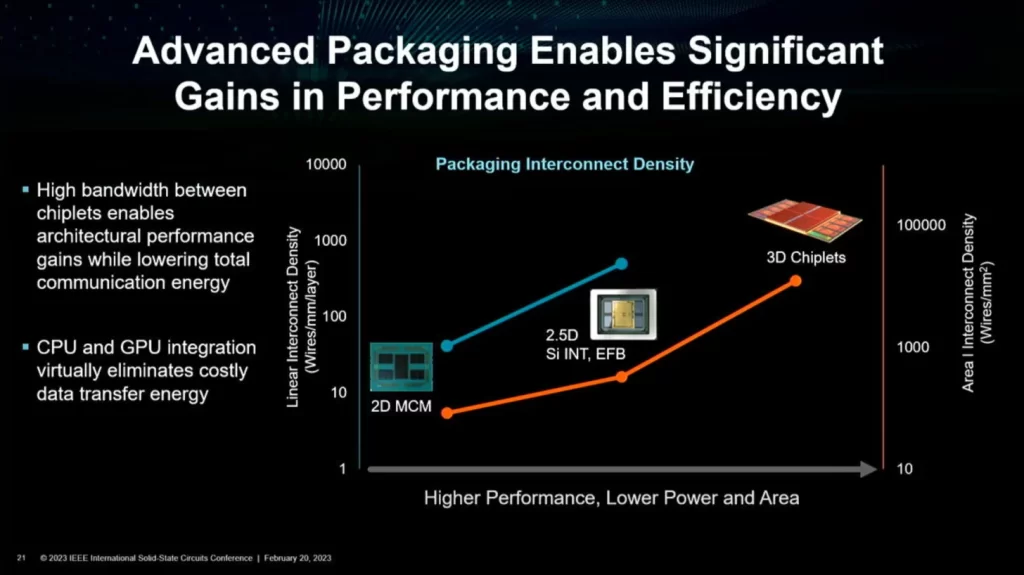
AMD aims to resolve this efficiency issue by innovating and utilizing creative packaging technologies. As per AMD, a 3D stacked approach is around 50x more efficient than an off-package copper solution.

3D Chiplets seem to be the future. when compared to a 2.5D approach, they are much more efficient and offer greater interconnect density. What’s better is that you can use a different process for the tile or a chiplet that contains I/O which doesn’t scale as well as logic.
The MI300 accelerator brings many changes to the last-gen MI250. Firstly, both the GPU and the CPU share the same memory, allowing the GPU to effectively draw data without the CPU’s interference.
Diagrams are fun, but they don’t tell the complete story. A mathematical or statistical result does that. AMD will achieve a similar growth with the MI300 as was the case with the MI250. This only increases the gap between AMD and the industry. This sudden rise in efficiency was slightly higher than what AMD projected, so that’s a win for the developers and the engineers.
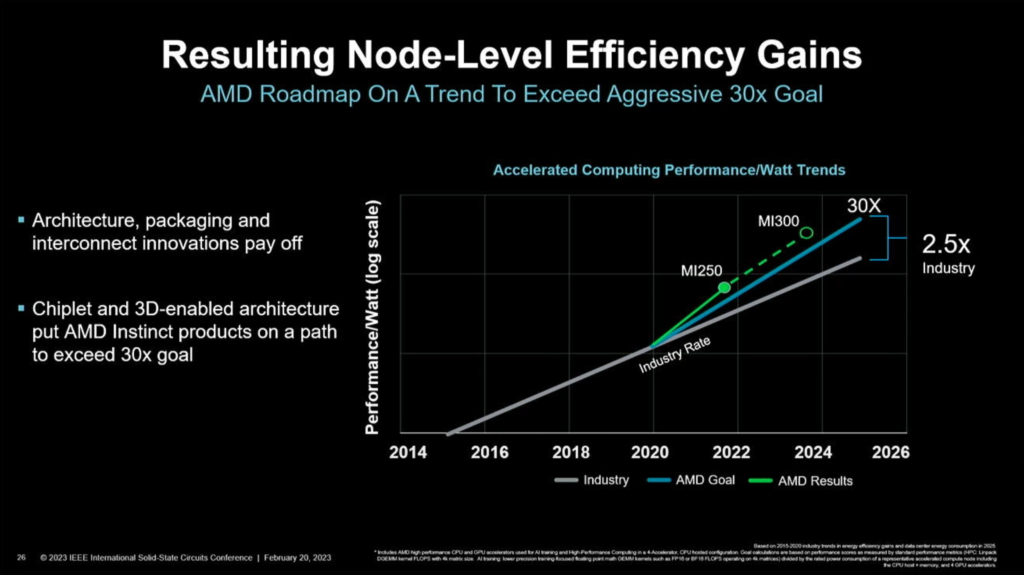
The Need for Innovation
A 3D hybrid bond of memory allows for 60x lead in efficiency when compared to the traditional DIMM standard. AMD has done this before, with Zen3XD and the upcoming Zen4X3D CPUs. Team red has effectively stacked SRAM or Cache in the form of chiplets which can drastically increase the performance in a few workloads, such as gaming.

AMD’s next-gen SiP is said to use advanced packaging technologies including a mix of 2D/2.5D and 3D packaging. Alongside that, it will feature heterogeneous compute cores, high-speed chip-to-chip interface (UCIe), Co-Package Optics, Memory layers, etc.
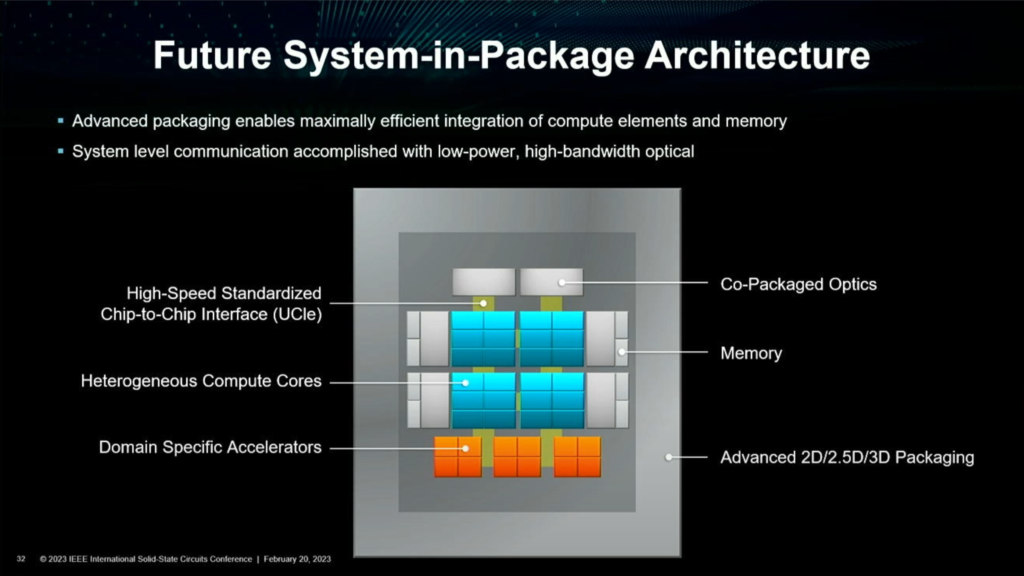
This allows for supercomputers in 2035 to hit the zettaflop mark at just 100MW (or less) of power. That’s roughly 5x less than what is currently being predicted but is doable. The aim is to hit 10,000 GigaFLOPS of performance per every watt consumed which is neither easy on paper nor is it in real life.






