Menu
Appuals
Search for
HOW-TO
Microsoft Windows
Messaging
Servers & Networks
Streaming
Printers
Apple
Android
Browsers
Gaming
Email
Smart Home
Chrome OS
Hardware
Linux
GPU
Social Media
REVIEWS
Graphics Card
Motherboards
Mice
Keyboards
Laptops
Audio
Cases
Coolers
RAMs
Storage
Power Supplies
Peripherals
Processors
Smart Gadgets
Pre-Built PCs
NEWS
LEARN
Coding
Search for
Follow
Facebook
Twitter
LinkedIn
YouTube
Android
April 6, 2024
Exclusive: Moto Edge 50 Pro Europe Price Leaked
Android
March 25, 2024
Exclusive: HONOR 90 Smart 5G Renders, Specs and Price Leaked
Android
March 20, 2024
Exclusive: POCO C61 Renders, Specs and Price Tipped for India
Android
March 17, 2024
Realme Narzo 70 Pro Storage & Color Options Tipped
Android
March 17, 2024
EXCLUSIVE: Vivo V40 SE 5G Renders, Specs & Price Leaked
Android
March 16, 2024
Android 15 Will Allow You To Find Devices Even When Powered Off
Industry
March 15, 2024
Samsung Memory Chip Business is Expected to Make a Comeback This Year, Profit Recovery Forecasted in H2 2024
Android
March 14, 2024
Samsung’s “Budget” Z Fold 6 FE Might Be the Key to Counter Huawei’s Dominance in the Foldable Segment
Industry
March 13, 2024
Snapdragon 8 Gen 4 May Push for LPDDR6 Support This Year, Apple A18 to Miss Out
Industry
March 13, 2024
Intel Foundry Drops Out of Top 10 as Leading Foundries See Strong Growth in Quarterly Revenue
How To: Microsoft
By
Muhammad Zubyan
April 19, 2024
How to Fix bthhfenum.sys BSOD on Windows?
Windows Troubleshooting
By
Hamza Mohammad Anwar
April 19, 2024
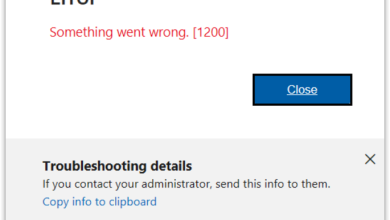
How to Fix Microsoft Error Code 1200 “Something Went Wrong”
Windows DLL
By
Hamza Mohammad Anwar
April 19, 2024
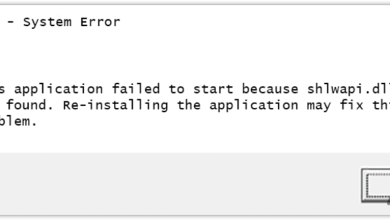
How to Fix the Shlwapi.dll Missing Error on Windows?
Windows Audio
By
Hamza Mohammad Anwar
April 12, 2024
How to Uninstall and Reinstall Your Audio Drivers on Windows?
Programs and Apps
By
Zainab Falak
April 12, 2024
How to Completely Uninstall uTorrent from Your Windows PC?
Streaming
By
Hamza Mohammad Anwar
April 19, 2024
How to Fix Twitch White Screen Issue?
Amazon
By
Khalid Ali
April 19, 2024
How to Update Fire TV Properly in 4 Easy Steps [2024]
Amazon
By
Hamza Mohammad Anwar
April 19, 2024
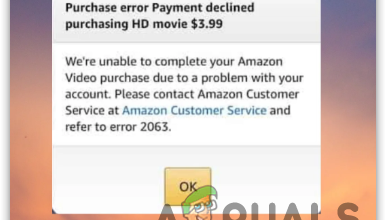
How to Troubleshoot Amazon Prime Video Error 2063
Kodi
By
Kevin Arrows
April 18, 2024
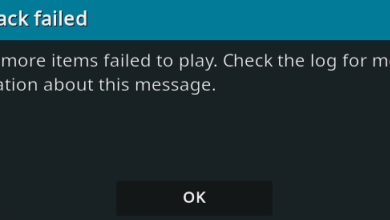
How to Fix Kodi Playback Failed Error
Streaming
By
Kamil Anwar
April 6, 2024
Answered: If I Cancel Audible, Do I Lose My Credits? [2024]
Gaming
Multi-platform
By
Abdullah Amin
April 19, 2024
How to Fix “Ea.Com/Unable-to-Connect” Error in EA Games?
Discord
By
Abdullah Amin
April 14, 2024
How to Fix Temporary Network Error on Discord? [2024]
PC Games
By
Hamza Mohammad Anwar
April 12, 2024
How to Fix Tekken 8 “UE Polaris Game has crashed” Error
PC Games
By
Hamza Mohammad Anwar
April 12, 2024
How to Stop League of Legends from Crashing?
Multi-platform
By
Hamza Mohammad Anwar
April 12, 2024
How to Fix ‘Logging into Online Services’ Error in MW3?
Apple
Apple
By
Muhammad Qasim
March 8, 2024
Apple’s First Foldable is Allegedly a 20.3″ MacBook, Not an iPhone
February 26, 2024
iPhone’s Upcoming 16 Pro Rumored to Feature a Periscope Lens
February 6, 2024
Vision Pro’s “Plastic” Face Cracks Quite Easily, Replacement Comes at $800
Windows
Windows
By
Farhan Ali
September 2, 2023
Microsoft Eliminating WordPad in Upcoming Windows Update
August 25, 2023
Windows Insider Preview Build 23531 Released for the Beta Channel
August 25, 2023
Windows Testing New Post-OOBE Experiences in the Latest Insider Preview Build
Industry
Industry
By
Muhammad Qasim
March 15, 2024
Samsung Memory Chip Business is Expected to Make a Comeback This Year, Profit Recovery Forecasted in H2 2024
March 13, 2024
Snapdragon 8 Gen 4 May Push for LPDDR6 Support This Year, Apple A18 to Miss Out
March 13, 2024
Intel Foundry Drops Out of Top 10 as Leading Foundries See Strong Growth in Quarterly Revenue
Tech
Tech
By
Farhan Ali
January 12, 2024
This Massive 165-inch 4K Display Can Fold into An Aluminum Slab in 30 Seconds
September 26, 2023
Xiaomi Smart Band 8 Active Renders, Specs & Price Leaked
August 23, 2023
France Working on Blocking Websites Through Browsers
Games
Games
By
Abdullah Amin
February 27, 2024
S.T.A.L.K.E.R. 2: Heart of Chornobyl: Everything You Need to Know
February 24, 2024
Clix Wins First-Ever Fortnite Match on the Apple Vision Pro
February 11, 2024
Rumor: One Piece, The Fantastic Four, FF7 Rebirth, and Many More Allegedly Coming to Fortnite
Android
Android
By
Sudhanshu Ambhore
April 6, 2024
Exclusive: Moto Edge 50 Pro Europe Price Leaked
March 25, 2024
Exclusive: HONOR 90 Smart 5G Renders, Specs and Price Leaked
March 20, 2024
Exclusive: POCO C61 Renders, Specs and Price Tipped for India
Apple
Mac
By
Muhammad Qasim
April 19, 2024
How to Turn Ringer Off on MacBook – 4 Easy Methods [2024]
iPad
By
Khalid Ali
April 14, 2024
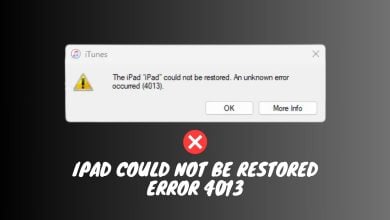
How to Fix “iPad Could Not be Restored” Error 4013
iPhone
By
Khalid Ali
April 6, 2024
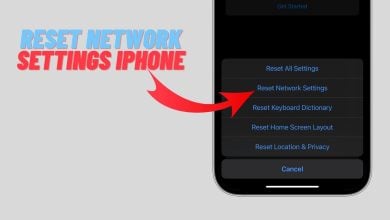
How to Reset Network Settings on iPhone in 5 Easy Steps
iPhone
By
Khalid Ali
April 2, 2024
11 Easy Fixes for When iPhone Brightness Keeps Changing
Apple
By
Kamil Anwar
March 31, 2024
How to Find My AirPods on Android: 3 Easy Ways [2024]
Servers & Networks
Network Administration
By
Kevin Arrows
April 1, 2024
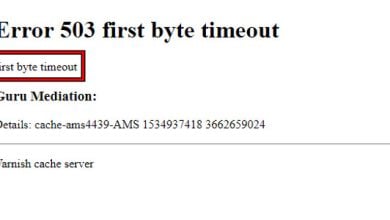
How to Troubleshoot and Resolve Error 503 First Byte Timeout?
Routers & Switches
By
Kamil Anwar
March 19, 2024
The 5 Best Routers for Spectrum in 2024 [Max Performance]
Virtualization
By
Abdul Mannan
February 19, 2024
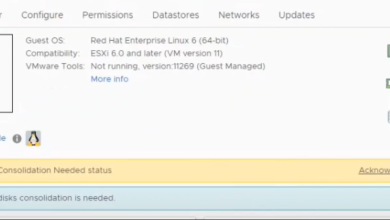
How to Fix ‘Virtual Machine Disk Consolidation is Needed’ Error in VMware?
Servers & Networks
By
Kevin Arrows
February 12, 2024
How to Fix Error 503 Backend Fetch Failed on Your Website?
Routers & Switches
By
Kevin Arrows
December 11, 2023
How to Fix a Spectrum Modem with Flashing Blue and White Lights
GPU
AMD
By
Hassam Nasir
November 4, 2023
How to Fix AMDRSServ.exe System Error in Windows?
NVIDIA
By
Raza Arshad
November 3, 2023
How to Fix Driver Download Failed Error in GeForce Experience?
NVIDIA
By
Muhammad Zubyan
August 1, 2023
What is Resizable BAR & Should You Enable it? (Guide)
AMD
By
Hamza Mohammad Anwar
July 9, 2023
Fix: Windows Update Automatically Replaced AMD Graphics Driver
NVIDIA
By
Kamil Anwar
May 28, 2023
Can’t Move Mouse in NVIDIA Overlay? Here’s the Fix!
Close
Search for
Close
Search for